# JIT
Hotspot JVM运行模式
JVM有两种模式, -client 和 -server. 从JDK5开始, JVM会根据机器的不同来决定使用哪种模式.
使用 java -version可以看到具体所使用的模式
$ java -version
java version "1.8.0_45"
Java(TM) SE Runtime Environment (build 1.8.0_45-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
在上面命令里,除了 64-Bit Server 这个吸引我之外, 还有一个东西很有意思. mixed mode
这是说明, Hotspot VM在默认情况下都是采用解释器+即时编译器的混合模式共同执行程序. 我们也可以指定不适用混合模式. 使用-Xint 和 -Xcomp即可.
[gambols-mbp15][zhenbao.zhou][~/work/java_works]
$ java -Xcomp -version
java version "1.8.0_45"
Java(TM) SE Runtime Environment (build 1.8.0_45-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, compiled mode)
[gambols-mbp15][zhenbao.zhou][~/work/java_works]
$ java -Xint -version
java version "1.8.0_45"
Java(TM) SE Runtime Environment (build 1.8.0_45-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, interpreted mode)
好,问题来了,解释器(Interpreter) 和 编译器 (compiled)是什么呢? 为什么需要者两个模式?
Interpreter解释器
为什么需要解释器
在JVM早期的发展过程时, JVM的开发人员为了实现跨平台, 不适用传统的静态编译的方式直接生成本地机器指令,而是实现了解释器(interpreter), 在运行时采用逐行解释字节码执行程序的想法.
解释器的工作原理
在程序运行的过程中, JVM根据预定义的规范对字节码采用逐行解释的方式执行,解释器将字节码文件中的内容“翻译”为对应平台的本地机器指令执行。当一条字节码指令被解释执行完成后,接着再根据PC寄存器中记录的下一条需要被执行的字节码指令执行解释操作
解释器的任务就是负责将字节码指令解释为对应平台的本地机器指令执行。在HotSpot VM中,解释器主要由Interpreter模块和Code模块构成。
- Interpreter模块 这个模块模块实现了解释器的核心功能, – 解释
- Code模块 管理JVM生成的本地机器指令.
编译器
明眼人预计都能看出来, 上面的解释器执行方式效率是有问题的. 因此Hotspot VM有弄了一个编译器. 通常叫做JIT编译器. Hotspot是怎么做的呢? 关于那些需要被编译为本地代码的字节码,也被称之为“热点代码”,JIT编译器在运行时会针对那些频繁被调用的“热点代码”做出深度优化,将其直接编译为对应平台的本地机器指令,以此提升Java程序的执行性能.
有哪些代码会被编译成本地机器指令呢?
-
Invocation Counter 会记录每个方法(method)的执行次数, 当次数大于某一个值的时候, JIT就认为这是一个”热”的方法, 并且编译成本地机器指令(natvie code). 在server模式时, 这个值默认是 10000. 可以通过 -XX:CompileThreshold=10000 来调节.
-
Back Edge Counter 记录每个循环里代码的执行次数. 如果这个循环里的代码执行次数大鱼某一个值时, 则会把循环里的代码编译成本地机器指令, 并替换掉.
总体来说, 可以由下面的图看出来JIT的执行
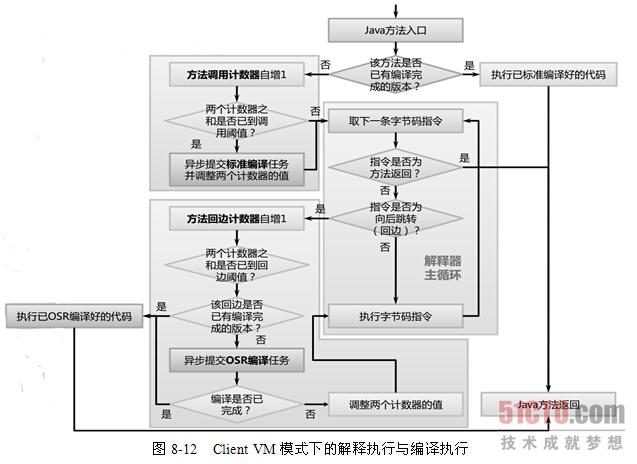
JIT编译器的组成
JIT编译器主要由C1模块、Opto模块和Shark模块构成。
- C1模块实现了Client Compiler编译器
- 而Opto模块实现了Server Compiler编译器,因此C2编译器也可以被称之为Opto编译器
- Shark模块中则实现了一个基于LLVM的编译器
分层编译策略(Tiered Compilation)
默认情况下, 使用Client模式时, 我们使用的是C1编译器. 使用Server模式时, 启用了C2编译器. 为了加快系统的启动速度, 在JDK7之后, 在Server模式后,默认开启分层编译策略.
在这种模式下,我们JVM的策略如下: 第0层. 由解释器解释代码执行, 并且解释器关闭代码优化的模块 第1层. 由C1编译器编译成本地机器代码执行, C1编译器执行少量的字节码优化. 第2层. C1编译器进行 invocation 和 backedge counter优化 第3层. C1编译器编译为本地机器指令执行,采集性能数据进行优化措施 (比 第二层慢 35%) 第4层. C2编译器进行完整的优化
TODO
没有明白的一个问题: 为什么要搞这么多层?还在继续研究
另外, jvm7之后, 有许多performance优化的点. 也可以继续学习
参考文献
- http://docs.oracle.com/javase/7/docs/technotes/guides/vm/performance-enhancements-7.html
- http://www.slideshare.net/maddocig/tiered
- http://book.51cto.com/art/201504/472757.htm
- http://middlewaresnippets.blogspot.hk/2014/11/java-virtual-machine-code-generation.html (待看)