CMS gc日志分析
本文适合稍微有一些jvm基础的人看
JVM内存结构
CMS,全称Concurrent Low Pause Collector,是jdk1.4后期版本开始引入的新gc算法,在jdk5和jdk6中得到了进一步改进,也是我们线上正在使用的垃圾收集器.
介绍cms之前, 先简单介绍一下JVM的内存结构. 下面这个图不错. 画出来了所有JVM里的内存块.
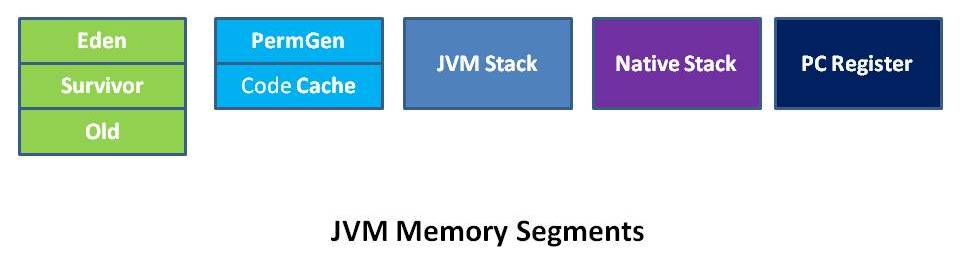
如图所示, 对于分代管理的垃圾收集器, HEAP分成三块.
- Eden: 存放最新进来的数据. 也叫Young
- Survivor: 一般分成s0, 和 s1, ygc时,将Eden的数据收集到s0或者s1.
- Old: N次ygc之后,还存活的对象, 会挪到Old区. Old区又叫Tenured
method area(方法区)其实不属于heap(堆). 在JDK8之前, 方法区和堆放在一起, 并且在FGC时,一起进行收集(虽然基本收集不出什么垃圾来)
在JDK8时, 方法区抽离出来单独放在了一个metaspace区. 不再和heap怼在一起了.
cms步骤
| 阶段 | 说明 | 是否会stw |
|---|---|---|
| Initial Mark | 单线程运行, 寻找离类加载器最近的live对象 | 是 |
| Concurrent Marking | 根据Initial Mark的结果的对象, 遍历Old区,找到所有的live对象. | 否 |
| Remark | 重新检查Concurrent Mark里增加或者删除的对象 | 是 |
| Concurrent Sweep | 找到mark过程中所有的标记为 dead的对象, 进行清除 | 否 |
| Resetting | 重置对象的状态 | 否 |
cms gc的触发条件
- 程序调用
System.gc()不过线上一般会在启动参数里加上DisableExplicitGC禁止这种做死行为 - old区剩余空间达到阈值 可以通过在启动参数里指定 CMSInitiatingOccupancyFraction来控制. 默认情况下, jdk5里的CMSInitiatingOccupancyFraction 为 68%, jdk6/7里为92%
- 永久代剩余空间达到阈值 忘了这个事情吧.
- YGC时提示: “promotion failed” 这是因为YGC时,S区域放不下这些对象,而此时Old区也放不下. 此时不一定是Old区剩余空间不足,也可能是晋升的对象需要连续的空间,而Old区连续的空间不足导致的。这个时候,也会触发cms gc
- concurrent mode failure 这是因为CMS GC的时候同时YGC进行着,导致CMS完成前老年代空间被占满(full promotion guarantee failure),这个错误会导致Full GC,导致GC时间变长,可以调小CMSInitiatingOccupancyFraction或调小新生代, 扩大Old区可用区域
promotion failed的解法
CMS回收的碎片化问题,基本是个无解的问题。常见的处理方式主要有:
- 减少应用产生对象的数量:降低CMS碎片化的产生的可能。
- 减少应用产生对象的大小:大对象容易触发老年代不足。比如当前剩余80M,如果对象是60M,那么可以放下;如果对象是100M,就放不小。
- 减少应用对象的生命周期:尽量在年轻代回收掉。
- 扩大年老代的大小:这种情况可以缓解,但是只是扩大了空间,延长了发生的时间。但是这种模式也可能有一定问题,由于堆变得更大了,可能造成整理堆的时间较长,外围停顿时间更长。
- 不用CMS, 用G1
cms参数以及含义
常见的CMS相关参数是:
- -XX:ParallelGCThreads = 3 YGC的线程数.默认为 (cpu <= 8) ? cpu : 3 + ((cpu * 5) / 8)
- -XX:ParallelCMSThreads = 1, CMS回收的线程数
- -XX:CMSFullGCsBeforeCompaction = 1, 在N次CMS gc后, 对old区进行压缩, 减少内存碎片
- -XX:CMSInitiatingOccupancyFraction=70. 出发CMS gc的内存使用比例阈值. 不过在使用过程中, 一般都在比这个小的阈值时,开始进行cms gc
- -XX:+UseCMSInitiatingOccupancyOnly. 如果指定了这个选项, 就不会出现上面的这个现象
- -XX:CMSScavengeBeforeRemark=true 在remark之前,促发一次ygc,减少remark所需要的时间
线上使用的参数是:
-Xms3072m 最小heap大小
-Xmx3072m 最大heap大小
-XX:NewSize=675m eden + Survivor 总共大小
-XX:PermSize=256m -XX:MaxPermSize=256M perm大小
-server 以服务器模式运行(其实默认就是这个)
-XX:+DisableExplicitGC
-verbose:gc
-XX:+PrintGCDateStamp
-XX:+PrintGCDetails
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintGCApplicationConcurrentTime
-XX:+PrintGC -XX:+UseConcMarkSweepGC
-XX:CMSFullGCsBeforeCompaction=1 (每次CMS都整理碎片)
-XX:+PrintSafepointStatistics
-XX:SurvivorRatio=8 (eden:s0:s1 = 8:1:1)
-XX:+TieredCompilation -XX:CICompilerCount=4 (分层编译, 最大有4个线程来编译, 成native code)
cms日志实例
initial-mark
2016-03-16T18:05:49.929+0800: 2613.504: [GC [1 CMS-initial-mark: 1227897K(2454528K)] 1261140K(3076608K), 0.0314290 secs] [Times: user=0.02 sys=0.01, real=0.03 secs]
CMS进入第一个阶段, initial-mark. 当时的情况是:old区总共大小为2454528K, 使用的大小为1227897K. 整个heap大小为3076608K, 使用了1261140K. 执行完成,总共花了0.03s
额,这里有一个问题是, 为什么使用比例才50%时就触发了cms呢?原因我也不知道.
concurrent-mark
2016-03-16T18:05:49.961+0800: 2613.536: [CMS-concurrent-mark-start]
2016-03-16T18:05:50.572+0800: 2614.147: [CMS-concurrent-mark: 0.611/0.611 secs] [Times: user=1.35 sys=0.26, real=0.61 secs]
进行concurrent-mark阶段.扫描live对象
concurrent-preclean
2016-03-16T18:05:50.572+0800: 2614.147: [CMS-concurrent-preclean-start]
2016-03-16T18:05:50.584+0800: 2614.159: [CMS-concurrent-preclean: 0.011/0.012 secs] [Times: user=0.02 sys=0.01, real=0.01 secs]
并发预清理, 花了0.01sec
concurrent-abortable-preclean
JDK5之后, CMS 增加一个并发可中止预清理(concurrent abortable preclean)阶段. concurrent abortable preclean段,运行在concurrent-prelcean 和remark之间,直到获得所期望的eden区占用率。
在这个过程中,一般也会伴随着一个ygc,来清理eden区. 这个过程中不会stop the world
2016-03-16T18:05:50.584+0800: 2614.159: [CMS-concurrent-abortable-preclean-start]
2016-03-16T18:05:50.858+0800: 2614.433: Application time: 0.8973190 seconds
2016-03-16T18:05:50.860+0800: 2614.435: Total time for which application threads were stopped: 0.0021890 seconds
2016-03-16T18:05:51.001+0800: 2614.577: Application time: 0.1411400 seconds
2016-03-16T18:05:51.014+0800: 2614.589: Total time for which application threads were stopped: 0.0121590 seconds
2016-03-16T18:05:51.298+0800: 2614.873: Application time: 0.2846280 seconds
2016-03-16T18:05:51.309+0800: 2614.884: Total time for which application threads were stopped: 0.0106730 seconds
2016-03-16T18:05:51.329+0800: 2614.904: Application time: 0.0198960 seconds
2016-03-16T18:05:51.331+0800: 2614.906: Total time for which application threads were stopped: 0.0023600 seconds
2016-03-16T18:05:52.655+0800: 2616.230: Application time: 1.3236740 seconds
2016-03-16T18:05:52.659+0800: 2616.234: Total time for which application threads were stopped: 0.0042470 seconds
2016-03-16T18:05:53.646+0800: 2617.221: Application time: 0.9869170 seconds
2016-03-16T18:05:53.648+0800: 2617.223: [GC2016-03-16T18:05:53.648+0800: 2617.224: [ParNew: 578034K->20882K(622080K), 0.0305740 secs] 1805932K->1250183K(3076608K), 0.0316520 secs] [Times: user=0.10 sys=0.00, real=0.03 secs]
2016-03-16T18:05:53.680+0800: 2617.255: Total time for which application threads were stopped: 0.0342680 seconds
2016-03-16T18:05:53.775+0800: 2617.350: Application time: 0.0943570 seconds
2016-03-16T18:05:53.777+0800: 2617.352: Total time for which application threads were stopped: 0.0021280 seconds
2016-03-16T18:05:53.940+0800: 2617.515: Application time: 0.1635230 seconds
2016-03-16T18:05:53.949+0800: 2617.524: Total time for which application threads were stopped: 0.0087670 seconds
2016-03-16T18:05:53.955+0800: 2617.530: Application time: 0.0059520 seconds
2016-03-16T18:05:53.960+0800: 2617.535: Total time for which application threads were stopped: 0.0046460 seconds
2016-03-16T18:05:53.964+0800: 2617.539: Application time: 0.0045690 seconds
2016-03-16T18:05:53.967+0800: 2617.542: Total time for which application threads were stopped: 0.0026540 seconds
2016-03-16T18:05:53.967+0800: 2617.542: Application time: 0.0001580 seconds
2016-03-16T18:05:53.968+0800: 2617.544: Total time for which application threads were stopped: 0.0014360 seconds
2016-03-16T18:05:54.001+0800: 2617.576: Application time: 0.0328520 seconds
2016-03-16T18:05:54.014+0800: 2617.589: Total time for which application threads were stopped: 0.0129880 seconds
2016-03-16T18:05:55.057+0800: 2618.632: [CMS-concurrent-abortable-preclean: 4.346/4.473 secs] [Times: user=9.41 sys=1.56, real=4.48 secs]
remark
2016-03-16T18:05:55.057+0800: 2618.633: Application time: 1.0430630 seconds
2016-03-16T18:05:55.059+0800: 2618.634: [GC[YG occupancy: 300145 K (622080 K)]2016-03-16T18:05:55.059+0800: 2618.634: [Rescan (parallel) , 0.0618970 secs]2016-03-16T18:05:55.121+0800: 2618.696: [weak refs processing, 0.0299250 secs]2016-03-16T18:05:55.151+0800: 2618.726: [scrub string table, 0.0029210 secs] [1 CMS-remark: 1229300K(2454528K)] 1529446K(3076608K), 0.0956850 secs] [Times: user=0.28 sys=0.00, real=0.09 secs]
2016-03-16T18:05:55.155+0800: 2618.731: Total time for which application threads were stopped: 0.0980400 seconds
这个阶段会暂停应用, 多线程对内存重新进行标记. 暂停时间较长
concurrent-sweep
2016-03-16T18:05:55.156+0800: 2618.731: [CMS-concurrent-sweep-start]
2016-03-16T18:05:55.250+0800: 2618.825: Application time: 0.0946000 seconds
2016-03-16T18:05:55.252+0800: 2618.827: Total time for which application threads were stopped: 0.0021380 seconds
2016-03-16T18:05:56.252+0800: 2619.827: Application time: 1.0001840 seconds
2016-03-16T18:05:56.257+0800: 2619.832: Total time for which application threads were stopped: 0.0048040 seconds
2016-03-16T18:05:56.291+0800: 2619.866: [CMS-concurrent-sweep: 1.131/1.135 secs] [Times: user=2.46 sys=0.42, real=1.14 secs]
concorrent-reset
2016-03-16T18:05:56.291+0800: 2619.866: [CMS-concurrent-reset-start]
2016-03-16T18:05:56.302+0800: 2619.877: [CMS-concurrent-reset: 0.011/0.011 secs] [Times: user=0.03 sys=0.02, real=0.01 secs]
2016-03-16T18:05:56.621+0800: 2620.196: Application time: 0.3636370 seconds