分布式锁
[toc]
作用
分布式锁的作用,说大不大, 说小也不小。 绝大部分时候,应该避免使用分布式锁。 原因是:这个玩意会让系统很复杂,使用起来容易死锁。 然后,确实在高并发的时候,需要用到这个功能。
实现
分布式锁的核心是,在一个中心的地方,设置一个字段,说明某个线程正在使用。根据中心的不同,有两个常见选择。 redis 和 zookeeper
基于redis的分布式锁实现
目前,已经有基于redis分布式锁的开源实现了。可以参考redis分布式锁找到对应语言的开源实现。java对应的开源实现叫redisson。
单实例
如果是单实例的redis的分布式锁实现, 比较容易。步骤大概是:
-
线程1
SET lock_name current_timestamp NX PX 30000// 设置当前时间为value, 并设置30s的expire时间 -
如果插入成功,则获取锁OK。 如果插入失败,则获取锁失败
-
代码执行完成后,要用一个lua脚本来完成DEL操作。(防止自己超时或者其他原因,删掉了别人持有的锁)
if redis.call("get",lock_name) == current_timestamp then
return redis.call("del",lock_name)
else
return 0
end
多实例
单实例的情况,如果master挂了,则锁就都傻逼了。于是有人提出了多redis实例的方案。
多实例的方案算法叫Redlock, 原理有点像zk的选举算法. 假设系统里,一共有N个redis实例, 如果想要拿到某一个锁, 必须至少要拿到N/2 + 1 redis实例的锁时,才算成功了.
算法还有一个精妙的地方是, 考虑了网络的延迟时间, 可以做到即使多个redis实例的系统时间即使不一致,也不会有问题.
假设一共有5个实例, 客户端获取锁的步骤是:
- 获取当前时间
- 用某一个key,轮流请求这5个实例,用随机值(记为X), 用
SET lock_name current_timestamp NX PX 30000去请求加锁. 如果某一个redis实例挂了,就尽快去请求下一个实例(给这个redis的连接设置一个很短的超时时间). - 客户端会记录5个node总共用到的加锁时间. 如果有3个(以及三个以上)实例设置成功啦,并且加锁时间< 锁的有效时间(这个实例里, 是30S). 则加锁成功. 这个锁的有效期是 30S - 加锁消耗的时间
- 如果获取锁失败, 则调用上文说的脚本,删除每一个已经加锁成功的redis实例里的锁
可以参考这个代码: https://github.com/gambol/redis-distributed-lock
基于zookeeper的实现
由于zookeeper天生nb的选举算法以及靠谱程度,所以也可以用zookeeper 来做分布式锁。实现方案非常简单。
-
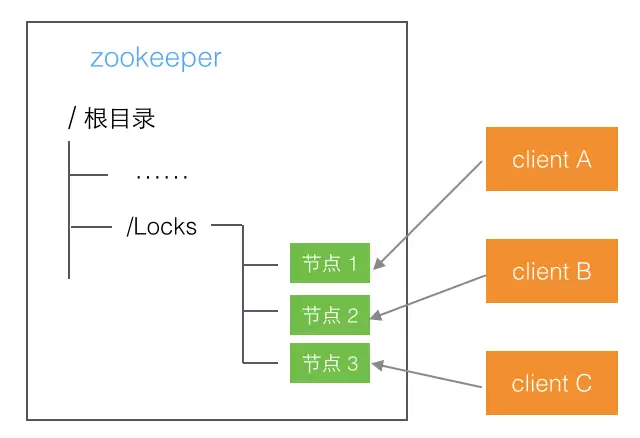
前提 在zookeeper中创建一个根节点(Locks),用于后续各个客户端的锁操作
-
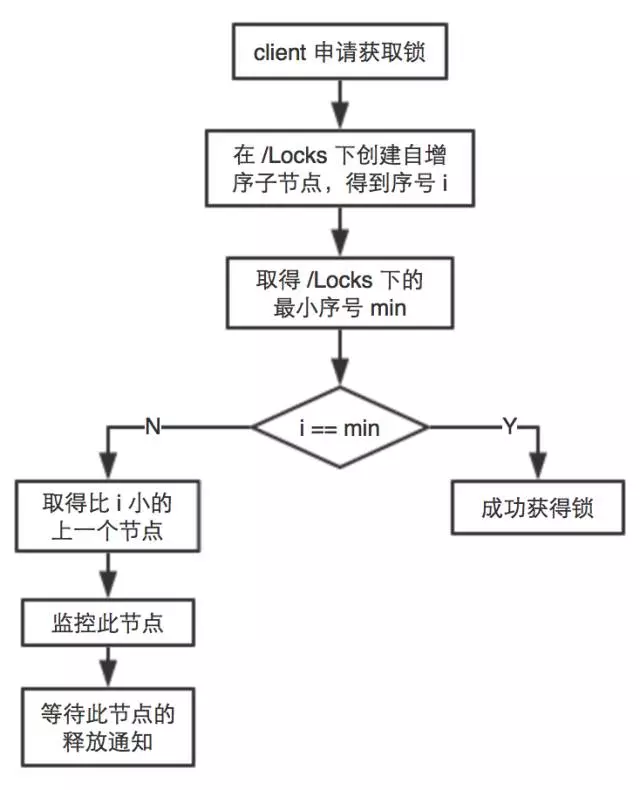
获取锁的过程 想要获取锁的client都在Locks中创建一个自增序的子节点,每个client得到一个序号,相当于排队 如果自己的序号是最小的,就成功获得锁 如果不是最小的,就关注自己前面的那个序号,发现前面那个走了以后,就轮到自己了
-
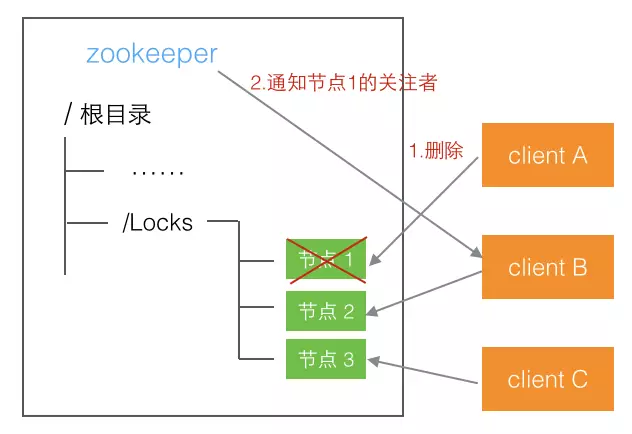
释放锁的过程 将自己对应的节点删除即可,下一个排队的节点就可以收到通知,从而被唤醒得到锁
参考文献
- http://mp.weixin.qq.com/s?__biz=MzA4Nzc4MjI4MQ==&mid=402727690&idx=1&sn=917f7a3e2023622df766aad58b7b9896#rd
- http://redis.io/topics/distlock
- http://blog.jobbole.com/95211/
- https://github.com/mrniko/redisson/blob/master/src/main/java/org/redisson/RedissonLock.java