kafka分享
用途
略
架构
拓扑结构
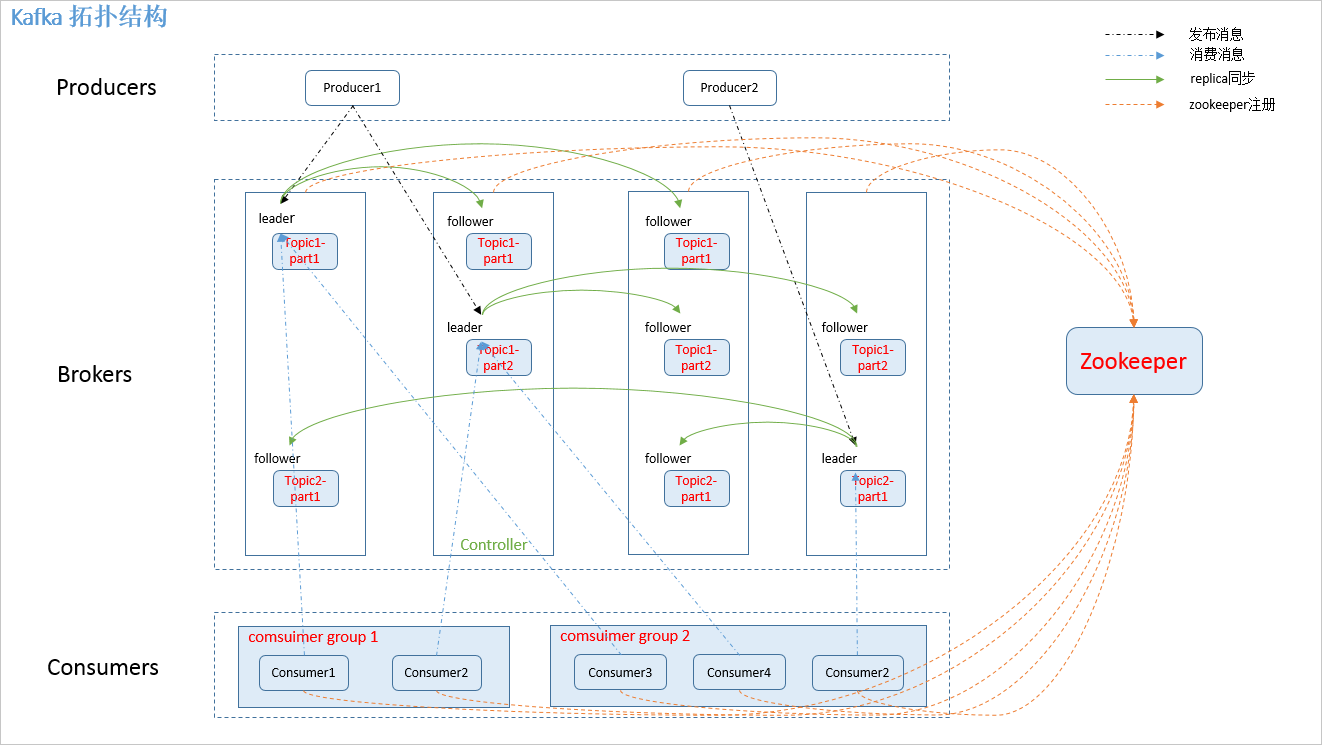
名词解释
- producer: 消息发送方
- broker: kafka集群的服务器 2.1 controller: 一个特殊的broker, 可以进行leader 的选举,或者failover的处理
- consumer: 消费消息的机器。
- consumer-group: 多个consumer属于同一个组。对于单条消息而言, 同一个group里,只有一台机器能收到
- topic: 发送到kafka的topic。每条消息都需要指定topic
- partition。 partition是物理上的概念, 用来持久化消息。 每个topic可以指定有几个partition。
- replica: 是一种机制,,保证partition的高可用 7.1 leader:一个特殊replica。 producer 和 cosnumer之和leader交互 7.2 follower: 从leader里复制数据
zk内容
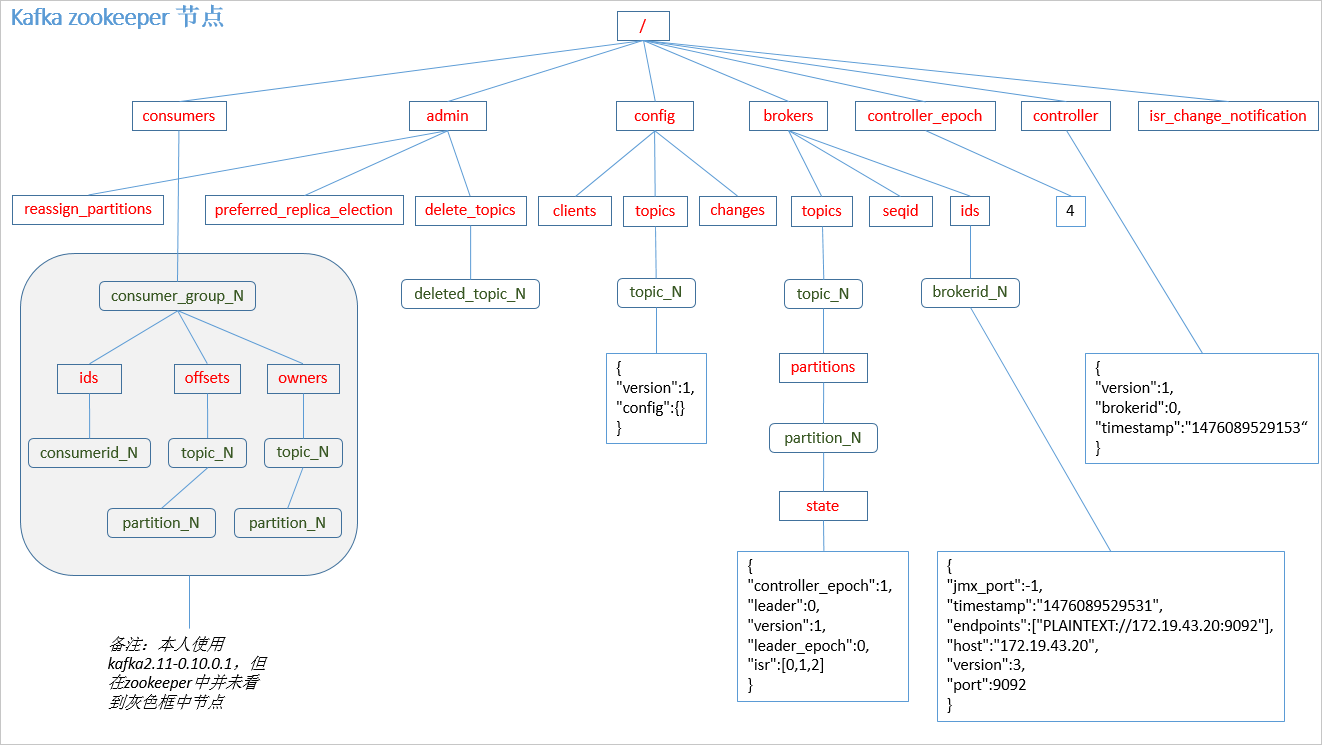
发消息
一. producer PUSH 到broker。 broker 顺序写入到对应的partition里
二. partition的选择策略:
- 如果api里制定了partition,则直接使用
- 如果没有partition,则根据key做hash,选出partition
- 如果没有key, 则客户端顺序选择
三. 时间序列
四. 默认 At least once
存消息
存储方式
一个topic, 多个partition。 每个partition对应一个文件夹。
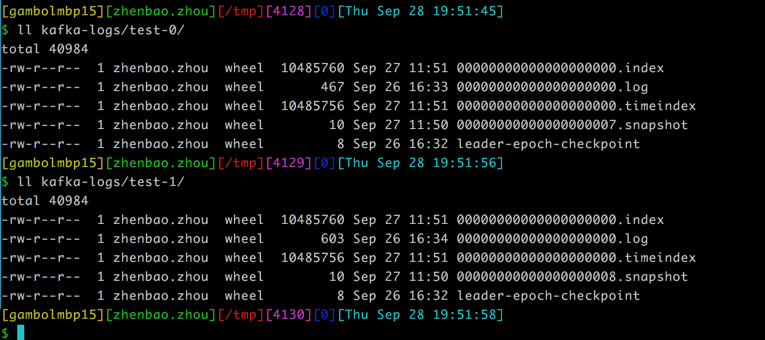
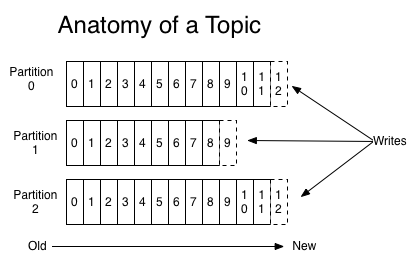
删除策略
- 基于时间
- 基于大小
消费消息
- high-level
- low-level
high-level
high-level consumer API 提供了 consumer group 的语义,一个消息只能被 group 内的一个 consumer 所消费,且 consumer 消费消息时不关注 offset,最后一个 offset 由 zookeeper 保存。
kafka 的分配单位是 patition。每个 consumer 都属于一个 group,一个 partition 只能被同一个 group 内的一个 consumer 所消费(也就保障了一个消息只能被 group 内的一个 consuemr 所消费),但是多个 group 可以同时消费这个 partition。
消费方式: pull — push 模式很难适应消费速率不同的消费者, 简化broker的设计。
讨论
consumer commit offset
参考 kafka文档
kafka在每个parttition里保存了每个consumer group最后的commit offset
consumer 的线程模型
- 模型一:多个Consumer且每一个Consumer有自己的线程,对应的架构图如下:
- 模型二:一个Consumer且有多个Worker线程
| 名称 | 优点 | 缺点 |
|---|---|---|
| 模型1 | 1.Consumer Group容易实现 2.各个Partition的顺序实现更容易 | consumer数量不能超过partition数量。 多的consumer永远用不到 |
| 模型2 | 横向扩展方便 | 多个partition上无法保证顺序处理 |
partition 和consumer的数量
- 如果consumer比partition多,是浪费,因为kafka的设计是在一个partition上是不允许并发的,所以consumer数不要大于partition数 。
- 如果consumer比partition少,一个consumer会对应于多个partitions,这里主要合理分配consumer数和partition数,否则会导致partition里面的数据被取的不均匀 。最好partiton数目是consumer数目的整数倍,所以partition数目很重要,比如取24,就很容易设定consumer数目 。
- 如果consumer从多个partition读到数据,不保证数据间的顺序性,kafka只保证在一个partition上数据是有序的,但多个partition,根据你读的顺序会有不同
- 增减consumer,broker,partition会导致rebalance,所以rebalance后consumer对应的partition会发生变化
如何自定义去消费已经消费过的数据
kafka console
参数说明
英文说明看kafka的document 中文说明看kafka配置说明
broker 的核心配置
- broker.id = 0 全局唯一的id。 正数
- port=9092 broker服务的端口
- zookeeper.connect=debugo01:2181/kafka,debugo02,debugo03 Zookeeper quorum设置。如果有多个使用逗号分割
- delete.topic.enable=true 是否允许使用工具删除topic
- num.partitions=2 每个topic的默认分区个数
- auto.create.topics.enable=true 是否自动创建topic
- log.dirs=/var/log/kafka 日志存放目录,多个目录使用逗号分割
- log.flush.interval.messages=10000 当达到消息数量时,会将数据flush到日志文件中
- log.flush.interval.ms=1000 当达到下面的时间(ms)时,执行一次强制的flush操作。interval.ms和interval.messages无论哪个达到,都会flush。默认3000ms
-
log.cleanup.policy = delete 日志清理策略(delete compact) -
log.retention.hours=168 日志保存时间 (hours minutes),默认为7天(168小时)。超过这个时间会根据policy处理数据。bytes和minutes无论哪个先达到都会触发。 - log.retention.bytes=1073741824 日志数据存储的最大字节数。超过这个时间会根据policy处理数据。
consumer
- bootstrap.servers=localhost:9092,localhost:9093 连接的broker地址 host1:port1,host2:port2,..
- heartbeat.interval.ms=3000 心跳
- enable.auto.commit=true 自动commit
- auto.commit.interval.ms=5000 自动commit的时间
producer
- bootstrap.servers=localhost:9092,localhost:9093 连接的broker地址
- request.timeout.ms =10000 消息发送的最长等待时间
- partitioner.class=kafka.producer.DefaultPartitioner 分区的策略,默认是取模